
Google publishes Gemma 3N, a multimodal SLM suitable for on-defense inference. The model takes advantage of a brand new architecture developed by Deepmind.
The team in charge of the Open Source Gemma family at Deepmind presented on the occasion of Google I/O 2025 Gemma 3n, its new reference SLM and most likely that of the market. The fully multimodal model (text, audio, video, image), was designed to be inferred on CPU.
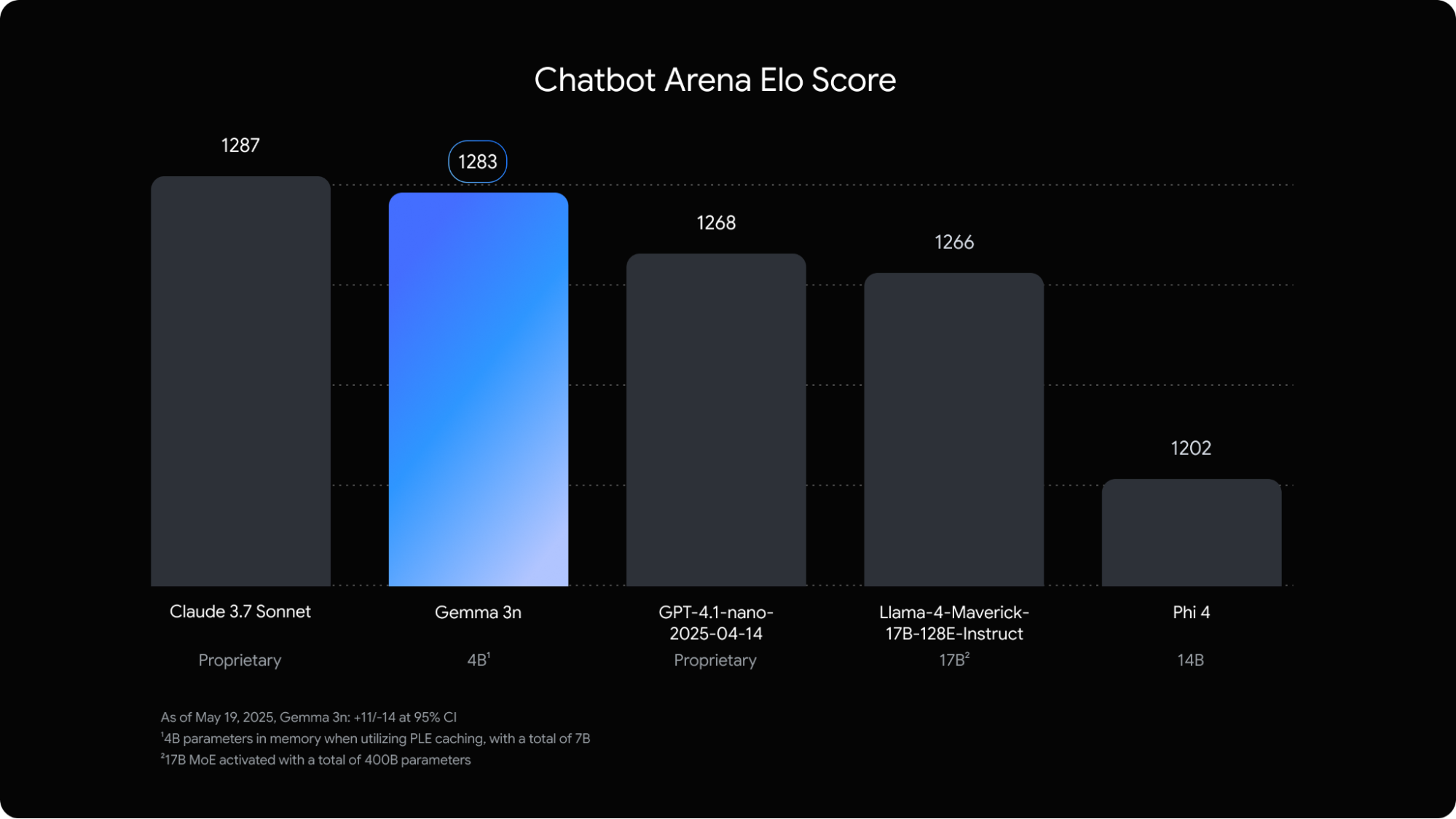
Gemma 3n, close to Claude 3.7 Sonnet in the Chatbot Arena
Gemma 3n is very strong in benchmarks, especially in view of its small size. On the Chatbot Arena, who measures user preferences anonymized, Gemma 3n obtains an Elo score of 1269, placing it just behind Claude 3.7 Sonnet (1289) and before GPT-4.1 or LLAMA-4-MAVERICK-17B. A small feat.
On more classic Benchmarks Gemma 3n displays solid results with 64.9% on MMLU, 63.6% success on MBPP, and 75.0% success on Humaneval. If we compare it to models of equivalent size, Gemma 3n then becomes Sota on the majority of benchmarks. A feat for a model which also has a reduced size to inference. For example, while Microsoft Phi-3 (14B) requires nearly 14 billion parameters to reach a MMLU score of around 62%, Gemma 3N actually only uses 4 billion active parameters to reach 64.9%.
🧠 Introduction: Miniaturizing AI Without Compromise
In an age when large language models (LLMs) dominate headlines for their billions of parameters and skyrocketing compute costs, Google has taken a bold new direction. With the release of Gemma 3n, a compact yet capable member of its Gemma 3 family, Google is pushing the envelope of on-device AI that rivals cloud-scale intelligence.
Why is this such a big deal?
-
Can AI models run locally without losing accuracy?
-
How does Gemma 3n compare with GPT-3.5 or Mistral 7B in quality?
-
Can small models actually support multimodal inputs and function calling?
-
What does this mean for edge computing, fintech, healthcare, and developer productivity?
This article explores the architecture, features, benchmarks, and real-world impact of Gemma 3n—Google’s answer to miniaturized, high-performance AI.
1. 🚀 What Is Gemma 3n?
Gemma 3n is the “nano” variant of Google’s Gemma 3 family of open-weight models, engineered to offer competitive performance in a tiny footprint. Released in 2025 as part of the Gemma 3.5 ecosystem, it builds on:
-
Google DeepMind’s Gemini architecture
-
TensorRT-LLM inference optimization
-
ShieldGemma safety classifiers
-
Multi-modal pretraining pipelines
Parameter sizes: Gemma 3n models range from 1.1B to 3.6B parameters, with memory and compute requirements 10x lower than their larger cousins—yet retaining up to 80–90% of their performance on key tasks.
2. 📊 State-of-the-Art Performance at Nano Scale
🧪 Benchmarks (Based on Google and third-party labs):
| Benchmark | Gemma 3n (1.1B) | Mistral 7B | Phi-3 Mini |
|---|---|---|---|
| MMLU (Zero-shot) | 42.8% | 59.8% | 48.7% |
| HumanEval (Code Gen) | 33.1% | 56.2% | 39.4% |
| GSM8K (Math, 5-shot) | 64.2% | 77.1% | 69.8% |
| ARC-Challenge | 54.7% | 73.4% | 58.2% |
Key takeaway: For its size, Gemma 3n leads in efficiency, making it the most performant model per watt among current nano-scale LLMs.
3. 🖥️ Designed for On-Device Inference
Gemma 3n runs entirely on-device using consumer or enterprise-grade hardware:
-
Smartphones and tablets (Android and iOS via TensorFlow Lite / MediaPipe)
-
Edge servers (using Nvidia Jetson, AMD EPYC, or Intel Xeon)
-
Local developer machines (via Ollama, Hugging Face Transformers, or Google AI Studio)
This is a paradigm shift—developers no longer need the cloud to deploy production-grade intelligence.
Latency: Average inference time of under 40ms per token on a consumer-grade M2 MacBook.
Cost: Runs with <1GB VRAM, enabling inference on Raspberry Pi 5 and equivalent microcontrollers.
4. 🌍 Multilingual & Multimodal: Small, But Not Limited
Gemma 3n supports:
-
140+ languages pretrained, including underrepresented ones like Yoruba, Bengali, and Navajo.
-
Vision-language tasks using adapters and LoRA finetuning.
-
Function calling and JSON output structuring—critical for agent-based systems and workflow automation.
This makes it ideal for:
-
Offline translation tools
-
Multimodal education apps
-
AI-powered medical assistants in low-connectivity regions
5. 🧩 Built for Modular Development & Fine-Tuning
Gemma 3n is developer-first:
-
Open weights on Hugging Face and Kaggle
-
Int8 / FP4 quantization supported via Google’s XLA compiler
-
Compatible with LoRA, QLoRA, and PEFT strategies
-
Easily integrated into LangChain, LlamaIndex, and TensorRT pipelines
For example, startups can:
-
Fine-tune Gemma 3n on custom enterprise documents
-
Deploy it in chatbots, edge devices, or autonomous agents
-
Maintain data privacy without sending data to external servers
6. 🛡️ Built-In Safety with ShieldGemma
Google has embedded ShieldGemma 2, an upgraded content moderation filter that:
-
Flags and blocks hate speech, toxicity, and explicit content
-
Works at the token level during generation
-
Can be customized by developers with new filters and guidelines
Compliance: Supports GDPR, HIPAA, and EDPB recommendations for AI systems—critical for finance, healthcare, and education sectors.
7. 🧠 Agentic Possibilities with Gemini Fusion
Gemma 3n can be used as a local reasoning agent in conjunction with:
-
Gemini Pro (cloud-based) models
-
Tool-use frameworks like ReAct, AutoGen, or CrewAI
-
Voice interfaces, via Speech-to-Text and TTS adapters
This means developers can run hybrid agents, where Gemma 3n handles:
-
Local input parsing and decision trees
-
Secure data retrieval or summarization
-
Low-latency offline tasks (e.g., route planning, smart home control)
🔚 Conclusion: A New Era of Miniature Intelligence
Google’s Gemma 3n is not just a technical feat—it’s a strategic move to democratize powerful AI. While the industry continues to focus on massive LLMs with massive compute needs, Gemma 3n signals a future where every phone, watch, or drone can house its own intelligent agent.
📌 Action Plan for Developers & Enterprises:
-
✅ Try Gemma 3n on Hugging Face
-
✅ Fine-tune for your vertical using Kaggle datasets
-
✅ Integrate with LangChain or Ollama for rapid deployment
-
✅ Use Google’s AI Studio for low-code prototyping
In the race to AI ubiquity, small is the new smart—and Gemma 3n is leading the charge.